




Greetings everyone and welcome back to another layman's blog. Before we go any further I'd like to thank you guys for showing all your love and support on my last blog, It really motivates me to keep going, I appreciate it 🙏
Alright then, today we are going to see what are the different types of Machine Learning systems/models. Now, before we do that let's take a small recap on what is machine learning. Because it never hurts to revise something 😉
Recap
Machine Learning is the science (& art) of programming computers so they can learn from data. We, as programmers, provide the machine with some inputs and some sample outputs. Then, let the machine figure out the rules by itself. Thus, learning from the data.
Arthur Samuel(1959): "Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed."
If you wish to read the full introduction to Machine learning, you can check out my previous blog.
Types of Machine Learning Systems
Machine Learning popularity is growing at an increasing rate, and almost very company is trying to implement it one way or another. Given that, do you think only a single Machine Learning system/model can achieve all the functionality. The answer to this is pretty obvious. So, what do we do? We classify these systems into different categories so as they can cover maximum area of functionality. There are so many types of Machine Learning systems, that it is useful to classify them in broad categories, based on the following criteria:
Note
These criteria are not exclusive; you can combine them in any way you like. For example, a spam filter may learn to label new email as spam on the fly using a deep neural network model, trained using examples of spam and ham. That makes it online, model-based, supervised learning system.
Let's take a look at each criteria a bit closely.
Supervised / Unsupervised Learning
Machine Learning systems can be classified according to the amount and type of supervision they get during the training. There are four major categories: supervised learning, unsupervised learning, semi-supervised learning, and Reinforcement learning.
Supervised Learning
In supervised learning the training set you feed to the algorithm includes the desired solution, called labels.
A typical supervised machine learning task is classification. The spam filter is a great example of this.
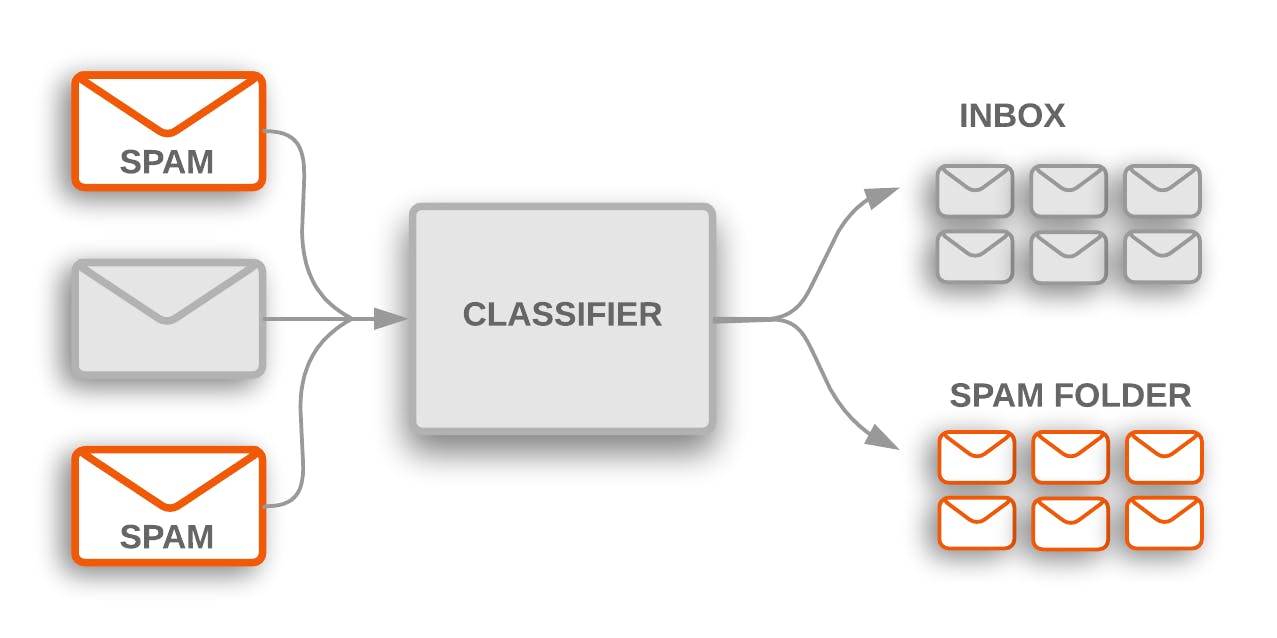
It is trained on many example emails, along with their class (spam or ham), and the model learns how to classify them.
Another typical task is to predict a target numeric value, such as a price of a car, given a set of features (color, brand, age etc.) called predictors. This sort of task is called regression. Training the model on a variety of cars and their prices. Then, using regression algorithm try to predict the prices of new cars.
Unsupervised Learning
In unsupervised learning, as you might have guessed, the training data is unlabeled. The system tries to learn without a teacher.
The goal of unsupervised learning is to find the structure and patterns from the input data. Unsupervised learning does not need any supervision. Instead, it finds patterns from the data by its own. One important unsupervised task is anomaly detection - for example, detecting unusual credit card transactions to prevent frauds, catch manufacturing defects or removing outliers from a dataset etc.
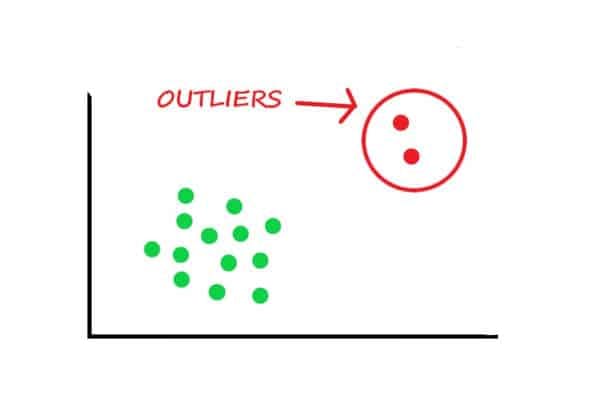
The system is shown mostly normal instances during the training, so it learns to recognize them. then, when it sees a new instance, it can tell whether it looks like normal one or whether it is likely an anomaly. Another similar task is novelty detection.
Semi-supervised Learning
Since labeling data is usually time consuming and costly, you will often find people working with data, that has plenty of unlabeled instances, and a few labeled instances. Some algorithms can deal with such partially labeled data. This is called semi-supervised learning.
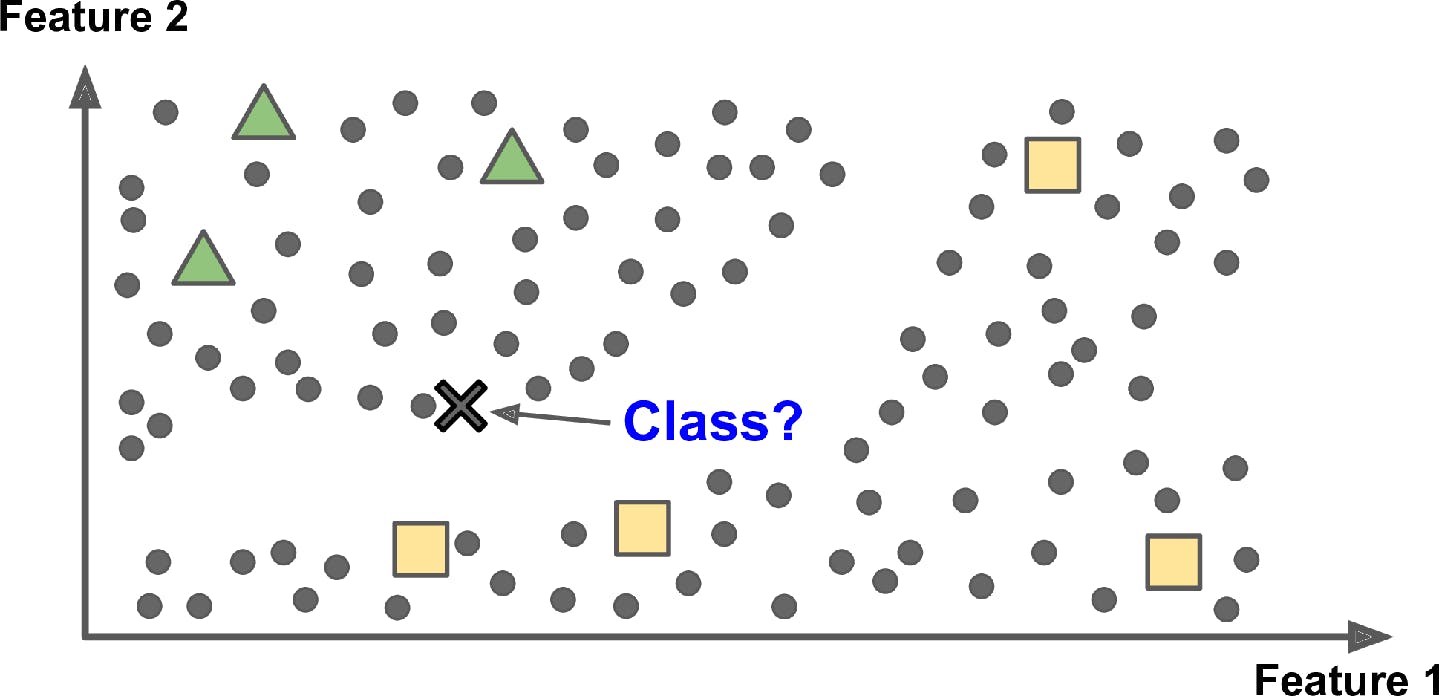
One of the most popular example of semi-supervised learning is Google Photos. If you upload all your family photos to this service, it automatically recognizes the same person. For eg, person A shows up in photos 1, 7, 15, while person B in photos 3, 8, 9. This is unsupervised part of the algorithm (clustering). Now all the system requires is for the user to tell who these people are. Just add one label per person and it is able to name them in every other photo.
Most semi-supervised learning algorithms are a combination of unsupervised and supervised algorithms.
Reinforcement Learning
Reinforcement learning is quite different as compared to others. The learning system, called agent in this context, can observe the environment, select and perform actions and get rewards in return (or penalties in the form of negative reward).
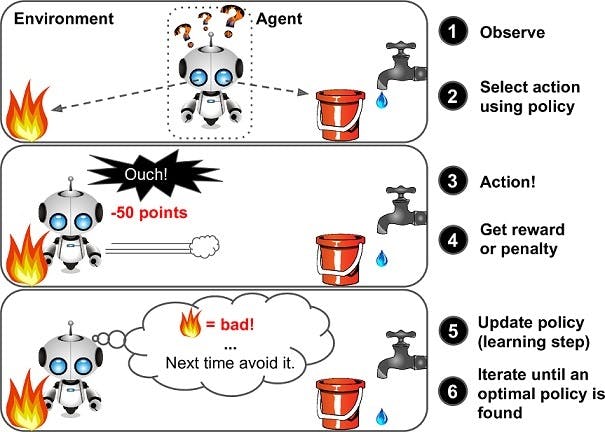
The system must learn from itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when given a situation. For example, many robots implement Reinforcement Learning to learn how to walk.
Batch & Online Learning
Another criteria used to classify Machine Learning systems is whether or not the system can learn incrementally from the stream of incoming data.
Batch Learning
In batch learning, the system is incapable of learning incrementally: it must be trained with all the available data. This will generally take a lot of time and computing resources, so it is typically done offline.
First the system is trained, and then it is launched into production and runs without further learning; it just applies what it has already learned. This is often also called offline learning.
If you want your system to know about new data, you need to train a new version of the system from scratch on the full dataset (not just the new data, but also the old data), then replace the old system with the new updated one.
While this kind of learning is not the best option, if you need your system to learn autonomously and it has limited resources (e.g., a smartphone application), for that matter this is a showstopper.
Online Learning
In online learning , you train the system incrementally by feeding it data instances sequentially, either individually or in small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives.
Online learning is great for systems that receive data as a continuous flow (e.g. stock prices), and need to adopt to change rapidly or autonomously. It is also a good option if you have limited computing resources: once an online learning system has learned about the new data instances, it does not need them anymore, so you can discard them. This can save huge amount of spaces.
Instance-Based & Model-Based Learning
Once more way of categorizing Machine Learning models is based on how they generalize. Most Machine Learning tasks are about predictions. This means that given a number of training examples, the system should make good predictions (generalize) for the examples it has never seen before.
Instance-Based Learning
Possibly the most trivial form of learning is simply to learn by heart. If you were to create a spam filter this way, it would just flag all emails that are identical to emails that have already been flagged by users--not the worst solution, but certainly no the best.
Instead, your filter should be programmed in such a way that it not only flags the emails marked by users, but also emails which are very similar to known spam emails. This requires a measures of similarity between two emails.
This is called Instance-based learning: the system learns the examples by heart, then it generalizes to new cases by using a similarity measure to compare them to the learned examples.
Model-Based Learning
Another way to generalize from a set of examples is to build a model of these examples and then use that model to make predictions. This is called model-based learning.
In this, we works with large datasets, study them and clean them if required. Then pick a suitable model depending on the dataset and type of predictions you wanna make. The model is then trained on the data and tested on validation data to check the accuracy of the model. If not, the model is tuned accordingly and retrained. This is done until the model doesn't start performing well.
A typical model-based machine learning goes this way:
Done for the day
That's it for today! I have learned a lot while writing this article, and I hope you did too. If you liked reading it please make sure to share it with your friends and colleagues.
You can follow me on twitter to get more updates on upcoming blogs.
Till then, keep coding 👨💻
Thank you 😊